In this post, we’re going to share the story of how we tackled the tough task of testing microservices. We’ll talk about the roadblocks we hit with traditional end-to-end testing and how these challenges pushed us to come up with our own solution for test automation. You’ll get an inside look at the steps we took to build a test automation platform that lets us confidently release new code.
Our Tech Ecosystem: A Quick overview
Before diving into the issue, let’s set the stage with an overview of our tech platform.
- Frontend languages and Frameworks: Our web application is written in React/TypeScript and tested using Playwright. Our mobile app is in Dart/Flutter and tested using FlutterTest.
- Backend for Frontend: We utilize the BFF pattern to orchestrate requests between the frontends and the myriad backend microservices. This BFF layer is written in TypeScript as well.
- Backend languages and Frameworks: All our microservices are written in Scala, leveraging the Akka framework. API testing is done using Cucumber-Scala.
- Containerized with Kubernetes: All services run in containers, orchestrated by Kubernetes.
- Multiple Environments and Regions: We operate in various environments like staging and production, spread across regions like Singapore and Hong Kong to serve the different markets where we operate our business.
The Challenges of Traditional End-to-End Testing
Endowus’ modern wealth management platform is a complex ecosystem consisting of numerous microservices, apps, languages & frameworks, managed by distinct engineering teams. While these teams enjoy autonomy in releasing changes independently, ensuring that the entire system functions seamlessly as a whole poses a considerable challenge. Why? Because microservices are complex systems made up of many moving parts - and when those parts interact, issues can arise.
As developers, we’ve meticulously developed unit tests for each microservice to ensure they work correctly in isolation. But how do we ensure that all the different parts of the system work well together?
Contract testing has often been applied in this context & it is indeed valuable for identifying breaking changes in APIs and data models. However, if there’s a significant overhaul in the data flow, robust runtime testing remains a critical necessity.
This led us to the adoption of end-to-end (E2E) testing across our entire platform. Adopting this approach brought along its own array of challenges.
Setup costs
While the tests were largely automated, the process of running the entire collection of tests against different configurations and environments remained a manual process.
Since setting up the variety of tests was a manual effort, testers often chose to run these only in the staging environment and due to this, blocked the environment from other needs. Because our services are loosely coupled and rely on eventual consistency, our e2e tests also take longer to observe and assert on the desired state. This further increased the time duration in which staging was unavailable for other needs.
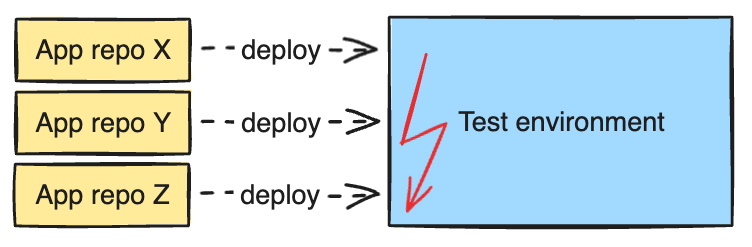
Feedback loop bottlenecks
Moreover, we had different kinds of end-to-end tests, like UI and API tests, that stretched the QA process. It also slowed down the feedback developers needed. After making their changes, developers found themselves in a waiting game for the QA team to run the tests and deliver feedback, a process repeated for every region we supported (Singapore and Hong Kong). Given that our platform across all regions operated on the same codebase, a fix intended for one region had the potential to disrupt another. The reality that some tests were not fully automated added another layer of complexity, requiring certain functionalities to be verified manually, which further extended the feedback loop.
Tracing test failures
Different engineering teams work on their codebases in parallel, making feature & bug fix code changes on their respective microservices as well as the frontend apps. When e2e tests are executed, they run against this lattice work of code changes in the different code repositories.
In such an environment, when a test failed, it became quite hard to trace the actual code change that caused the failure.
Data dependencies
As is typical in testing, many of our e2e tests relied on setup or fixture data to be present before tests can be run. This could be in the form of dummy client data, market data, dummy trades, etc., depending on the specific scenario being tested.
While our tests were automated, the process of setting up this data often wasn’t. Because we ran the tests in the same staging environment most of the time (see section above), teams came to rely on the data already present in this environment or to setup data manually once before creating new tests.
Thus, automated end-to-end tests that passed in one environment often failed in another due to their reliance on data that had been manually configured within each specific environment.
Skipping tests / ignoring failures
Due to this combination of lengthy testing procedures, data dependencies, versioning complexity, when teams encountered failing tests or tests that didn’t even run, they started applying their judgement on the risk to a production release posed by the test failure. Based on this judgement call, teams would go ahead with a production release despite e2e tests failing. While these calls were generally right, we were always at risk of a bad judgement call leading to production issues.
Decoupled test results from production releases
With manual execution of end-to-end tests, there was often a lack of clear documentation on which service versions were tested, which posed issues for audit trails.
The Vision for QA Evolution
Given these challenges, it became clear that we needed a new strategy to run our suite of automated end-to-end tests. The essence of this new strategy was to run all our tests - including e2e tests - within our CI/CD pipelines.
We were already running unit tests within our continuous integration build & test pipelines. CI/CD pipelines are a great way to ensure:
- Fully automated test execution
- Isolation of data / versions
- Auditable test artifacts
These were exactly what we needed to address the challenges faced in our e2e testing! Thus, by integrating e2e tests into our CI/CD pipelines, we had the potential to not only solve the current problems but to also strengthen our overall continuous delivery practices.
That sounds easy enough?
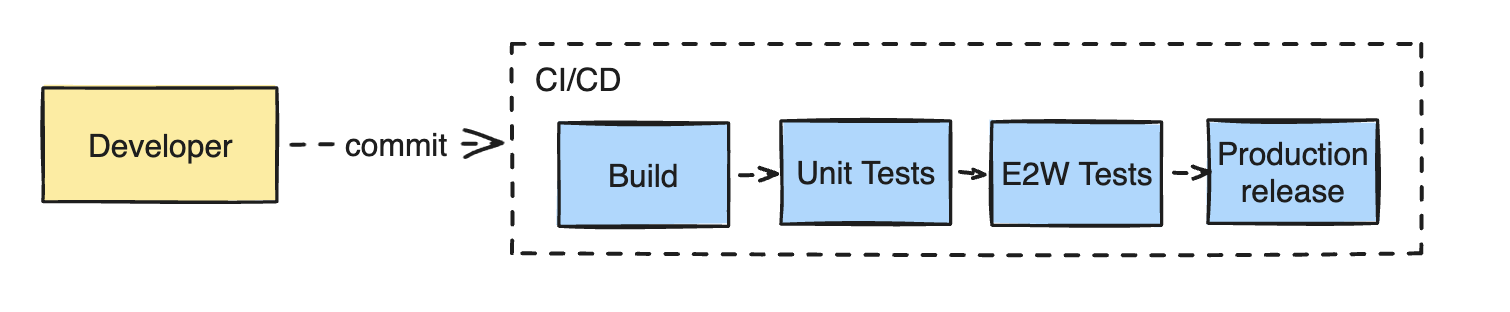
The pipeline integration might seem trivial if all services were deployed from the same application repository. But our wealth platform is quite complex, consisting of over 30 services spread across multiple repositories, all deploying to the same environment.
This raises a couple of crucial questions: How do we ensure that end-to-end tests assess a specific version of services without being interrupted by new deployments?
Moreover, how do we keep up with the high velocity of application changes in each of the repositories? A CI build pipeline is triggered for every single commit to the code repository. If we were to run end-to-end tests for every single commit of every repository, the tests would never be able to catch up.
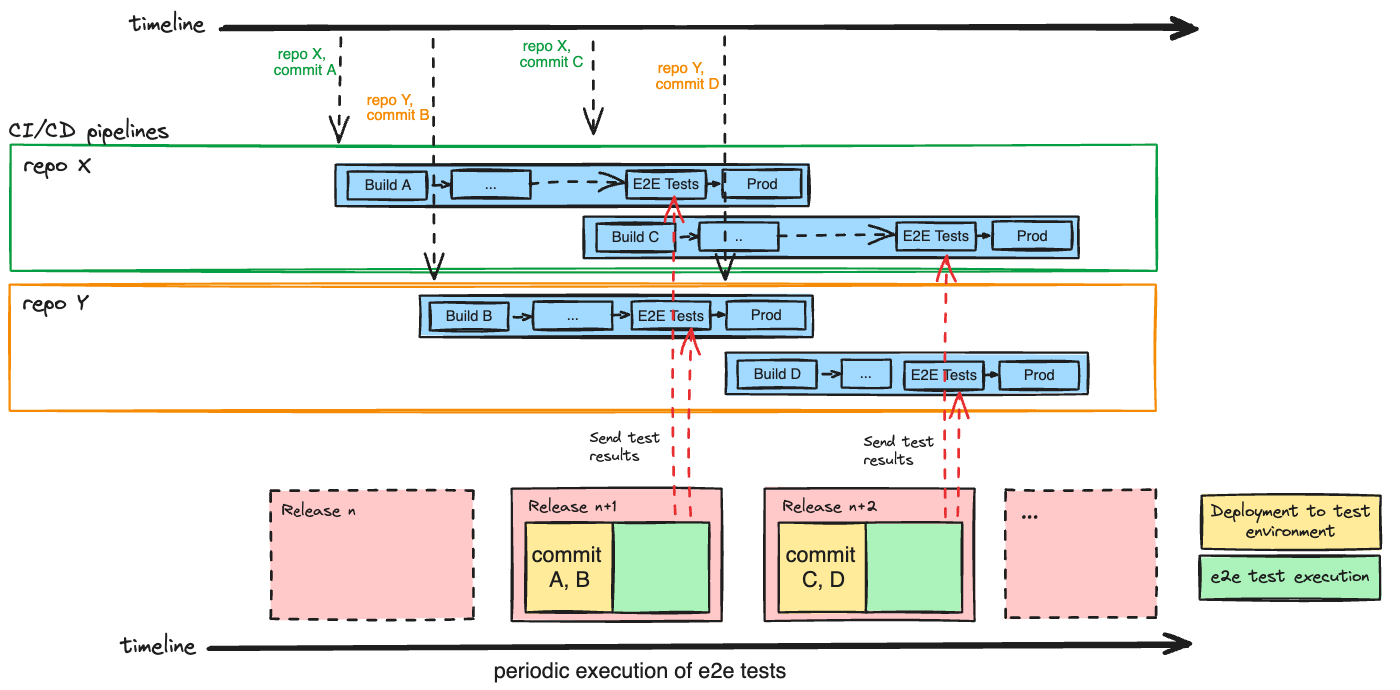
So we asked ourselves: What if we don’t have to run end-to-end tests on every single commit? This prompted us to consider shifting from a “push-based” to a “pull-based” approach.
“It really works to tackle much of life by inversion where you just twist the thing around backwards and answer it that way.. All kinds of problems that look so difficult, if you turn them around, they are quickly solved.” – Charlie Munger
Typically, unit tests follow a push-based approach, where tests are triggered by new commits to a branch.
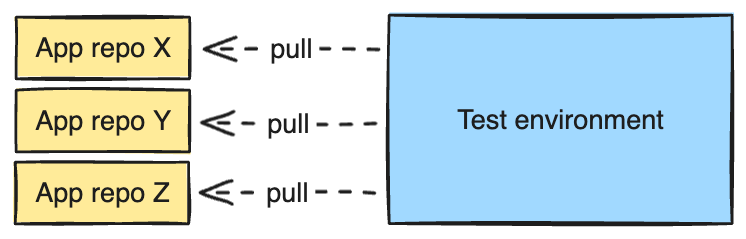
Adopting a pull-based approach would mean that end-to-end tests are periodically executed, using the latest code pulled from all application repositories, rather than being triggered by every single commit.
The end-to-end test results would be fed back into the individual application pipelines, providing us with concrete evidence of end-to-end testing for every production release.
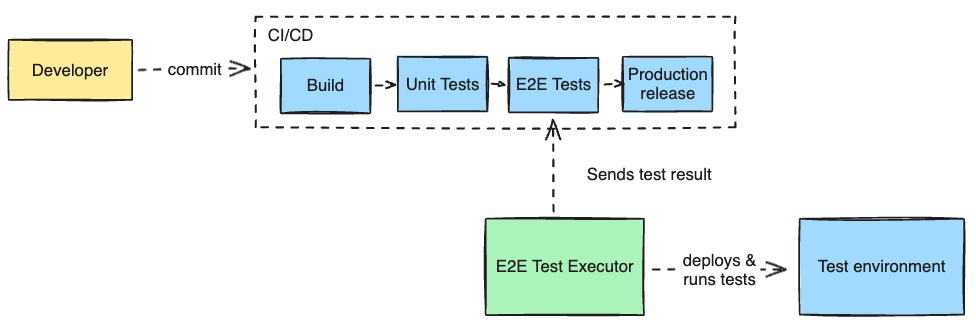
With this vision in mind, we developed an approach to microservice testing that enables us to confidently ship new code despite the complexity.
Levelling up our test automation platform
We’ve created a test automation platform that periodically orchestrates both the deployment and the execution of end-to-end tests inside isolated production-like environments. You can refer to our previous post to learn how we dynamically provision & manage these environments at scale.
Our platform ensures that test runs remain uninterrupted by new deployments. Importantly, it doesn’t necessitate end-to-end testing for each individual commit. Instead, code changes from any of the application repositories that occur during a test run will be grouped together and deployed, then tested in the next test cycle. This creates a seamless flow of continuous deployment and test execution.
This new platform has become the primary method for conducting end-to-end testing of our services before production releases. Our engineers receive notifications about any test failures directly through Slack and within their CI/CD pipelines.
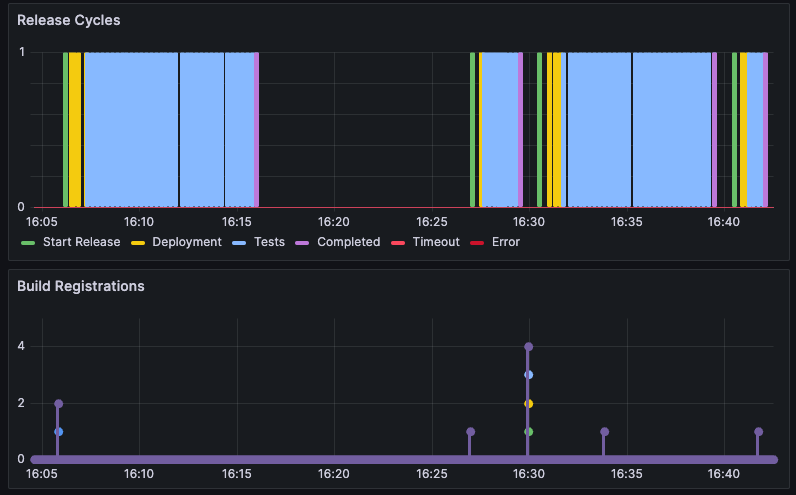
As of today, the deployment for multiple services typically takes less than 5 minutes, and the test runs less than 15 minutes. Consequently, the feedback loop between a code commit and knowing whether the changed code works as expected in multiple regions has been reduced to 20 minutes, a significant improvement compared to manual execution by QA engineers, which can take hours or days!
The quality of our product has improved as well since we are able to catch more bugs before going live in production. We’ve managed to catch critical issues, like applications not starting up properly or services failing to communicate and consume messages from each other – problems that could have led to serious incidents if left undetected.
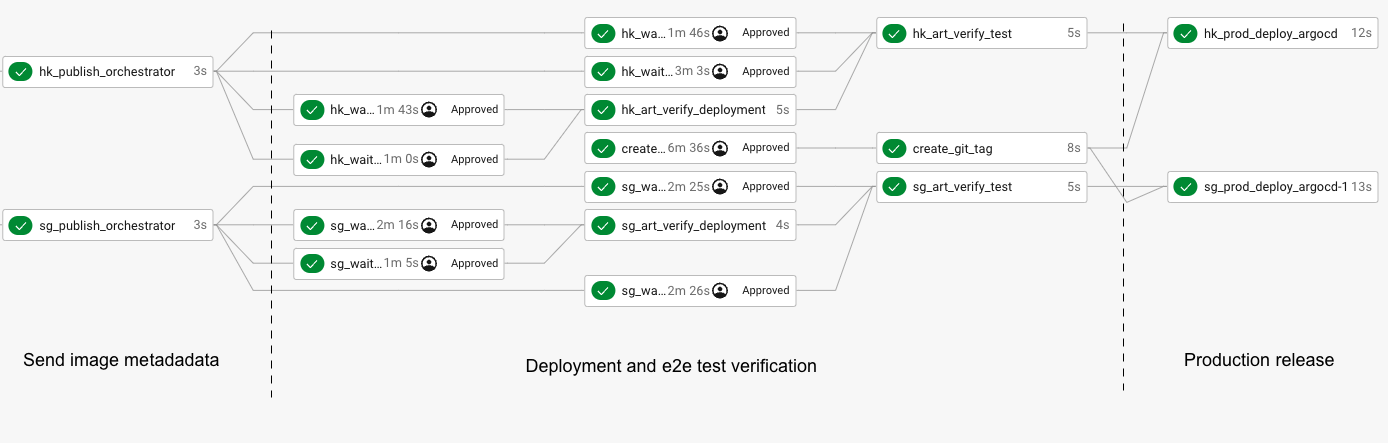
How did we do it?
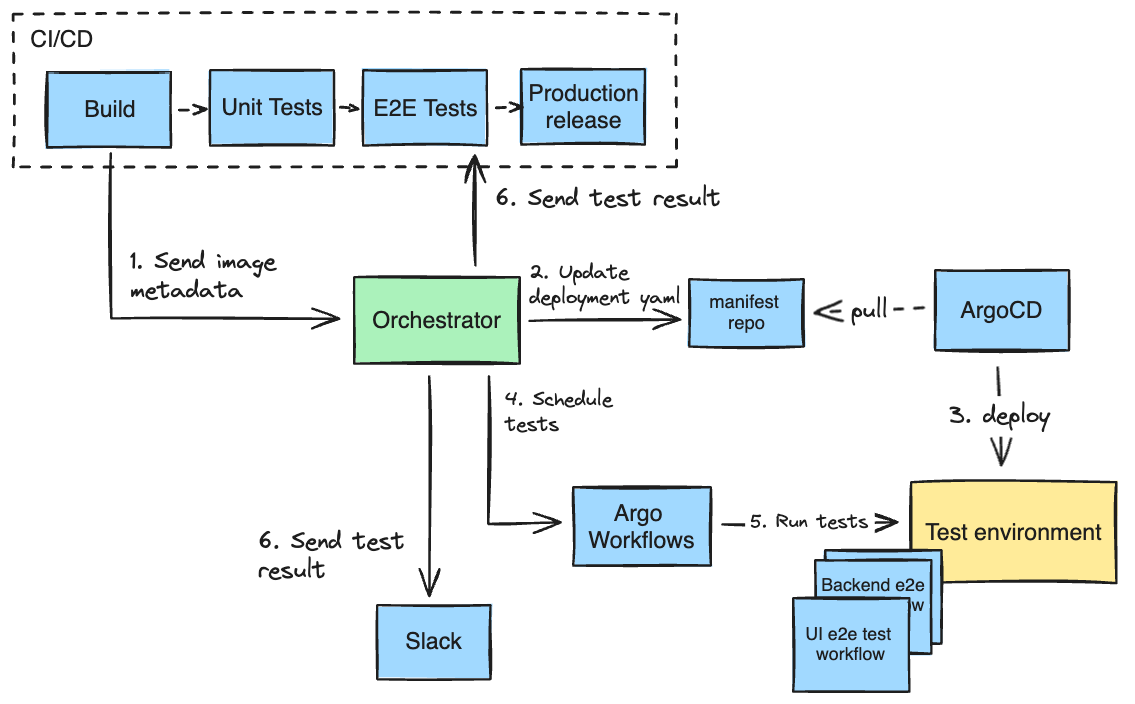
To manage continuous deployment and end-to-end tests in our test environment, we developed an orchestration service using Spring Boot. With each new build on CircleCI, this service receives metadata about the service changes, including the commit hash, container image, and the ID of the CI pipeline. When it’s time to start a new release cycle in the test environment, the orchestration service uses a GitOps approach via ArgoCD to update the environment with the latest service changes before kicking off the end-to-end tests.
We’ve adopted Argo Workflows as our test execution engine, which enables us to support different testing scenarios and frameworks used by various teams. For instance, our backend API end-to-end tests are built with Scala and Cucumber, while our UI end-to-end tests utilize Playwright. We also have other requirements, such as Dynamic Application Security Testing, which need to be executed at runtime. Each type of test is defined as a separate Argo workflow. These workflows are executed in parallel during a test cycle, allowing us to efficiently manage the diverse end-to-end testing needs of our platform.
Enhancing the quality of end-to-end tests
Running end-to-end tests presents a unique set of challenges. They’re inherently more prone to flakiness due to the complexity of the systems they cover, and they require significantly more time than unit tests, making it infeasible to test every commit. That’s why end-to-end tests are often placed at the top of the testing pyramid. Thus, to fully realize the benefits of end-to-end testing, it wasn’t sufficient to just solve the automation problem. We also had to address these challenges of long test runs & test flakiness.
To cut down on test execution time and provide developers with timely feedback, we focused on optimizing the feedback loop. We have implemented strategies such as executing only a subset of tests based on the services that have changed, and we have enabled the parallel execution of test scenarios whenever feasible. We also created environment-agnostic container images of the tests, which meant we could use the same images across all environments without the need for time-consuming rebuilds. By containerizing our tests, we eliminated the need for compilation during test runs. Additionally, we collaborated closely with test owners to address test flakiness using different strategies such as introducing retries and adjusting timeouts where necessary.
Conclusion
Testing microservices can indeed be challenging, but it’s a challenge that can be met with the right mindset and strategy. While ‘shift left’ testing is always advisable for early bug detection and smoother development cycles, we firmly believe in the value of thorough end-to-end testing. That’s the driving force behind our investment in creating a robust test automation platform.
Transitioning from manual end-to-end testing to an automated testing framework has been transformative for the development process of our wealth management platform. This shift has not only shortened the time it takes to receive feedback but has also markedly improved product quality, bug detection, and the overall efficiency of our testing procedures.
Moreover, the new test automation platform spearheaded a cultural shift towards mandatory end-to-end testing prior to production releases. Its adoption required cooperation by all teams and has heightened developers’ awareness of the importance of writing and maintaining reliable end-to-end tests. With the test execution process fully automated, our QA engineers can now focus their time and effort on creating test strategies for new initiatives, writing and refining test cases, and on exploratory testing.