At Endowus, we believe that happy & productive developers create products that customers love. Thus, we regularly invest in developer experience and in this post, we are sharing the story of one of our larger investments in this area. The story of how we increased our engineering productivity by building an internal platform that allows our developers to deploy and test our full digital wealth platform in isolated production-like environments.
Once upon a time
In the early days of Endowus, we had a small engineering team that would build features and deploy in a shared dev environment. When a feature was stable, it was promoted to a shared staging environment for QA before getting pushed to production. A simple, straightforward pipeline.
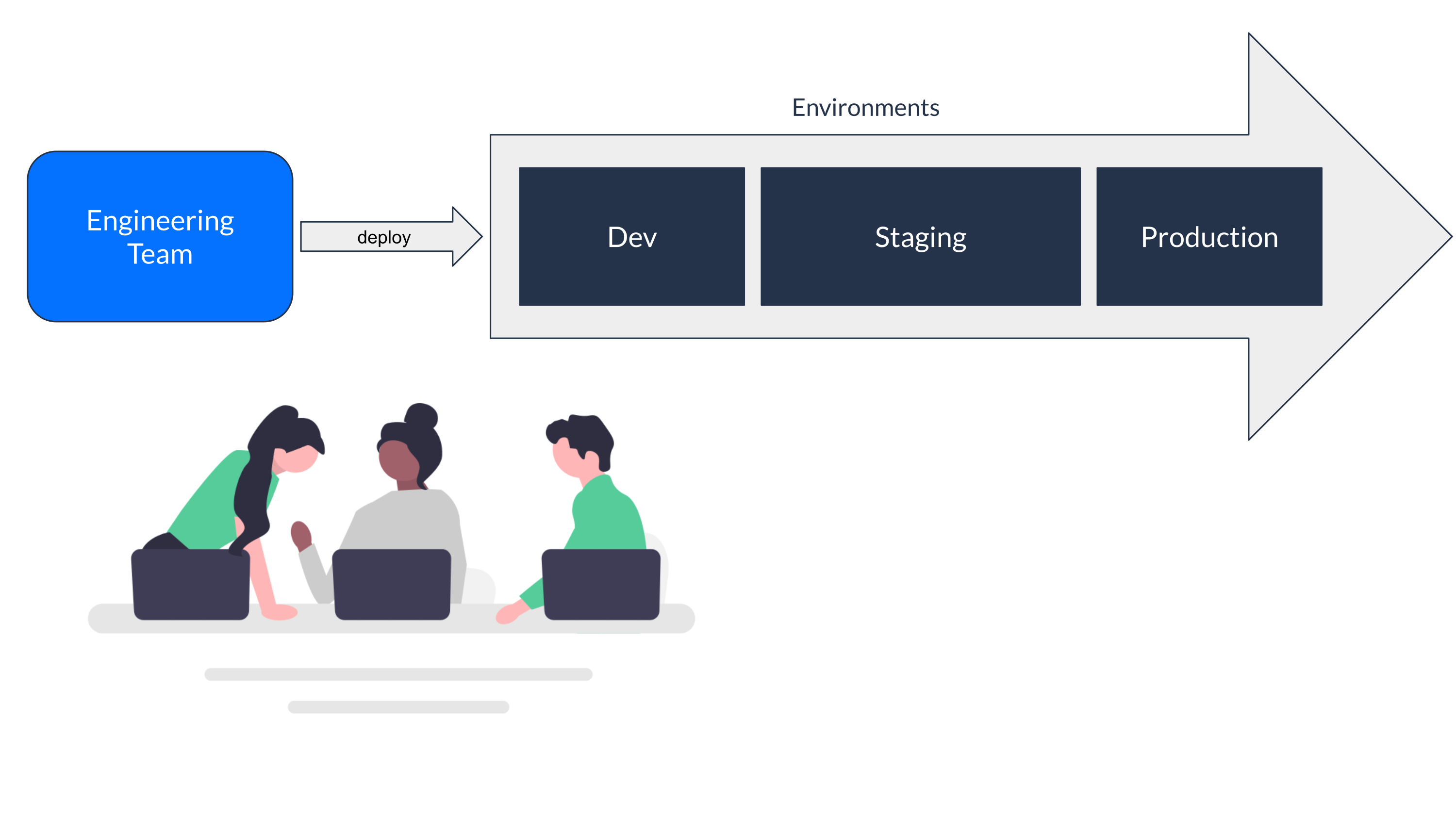
Since our public product launch in 2019, we have grown significantly as a company, and that one small engineering team grew to multiple teams, all trying to get their work done using the same shared dev and staging environments. We had more needs for those shared environments as well, e.g., regression testing, reproducing production bugs, running penetration tests, etc.
The Problem
With just one dev and staging environment across all teams and use cases, we quickly ran into several problems.
First, there was a lack of isolation between the work of each team. Teams were overwriting each other’s changes leading to wasted time and effort. Moreover, because of the lack of isolation, environments were often left in a corrupted state and it sometimes took days to restore an environment to a usable state.
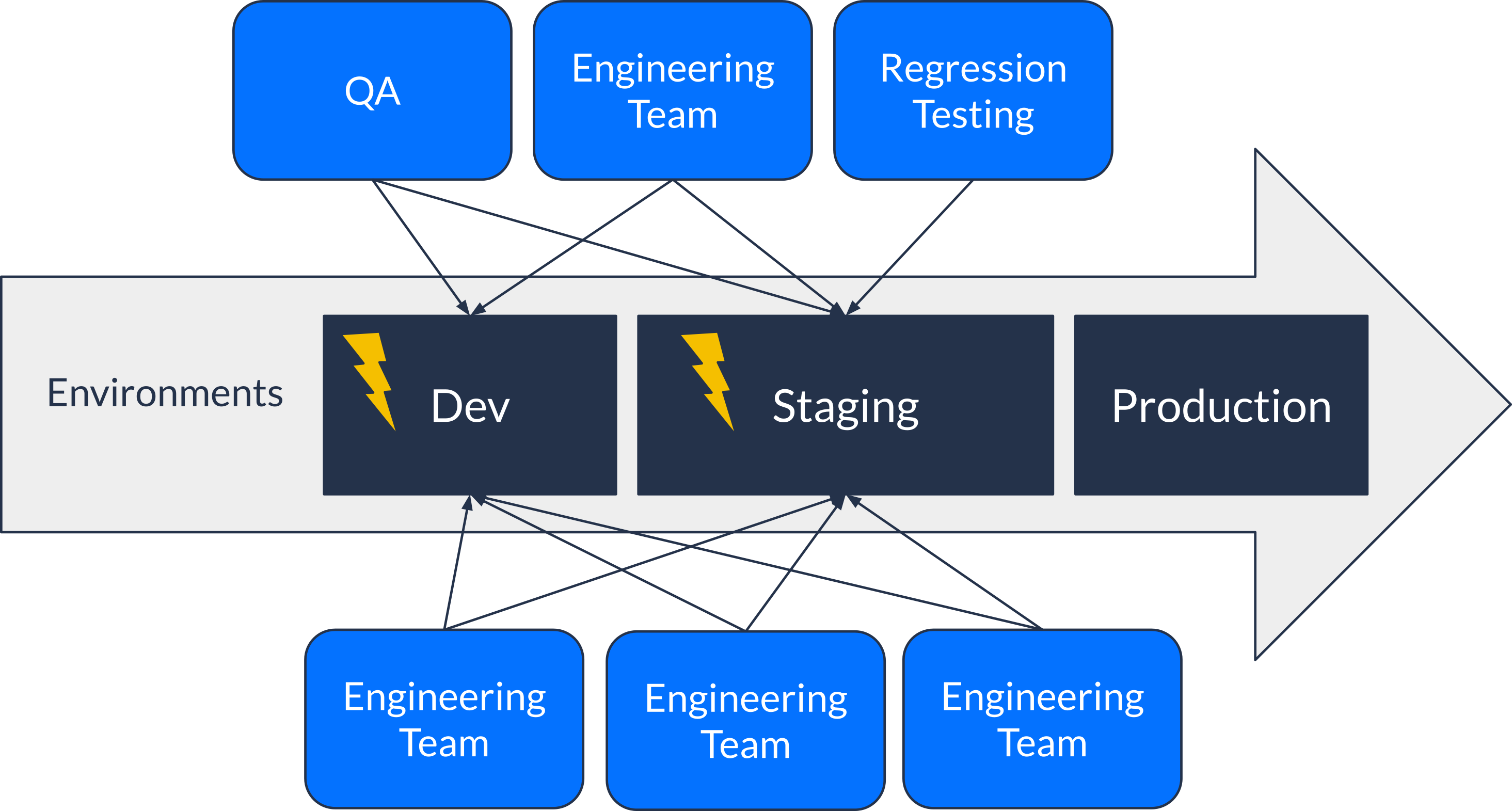
We tried to work around this by scheduling usage of these shared environments but it just slowed down our entire SDLC because the environments became a resource bottleneck. To make matters worse, some developers started testing less and bypassed some of the quality gates just to get releases out of the door. All of this was putting tremendous strain on the quality and speed of our software delivery, not to mention the impact on team morale.
The usual advice in this situation is to make sure that every developer can develop and test every change on their local machine. To do so, they should be able to spin up the entire application on their local machine. We tried to do that as well. But it becomes almost impossible to do so when the application is actually not one process but a dozen microservices, a handful of databases, a message queue, object storage, and more. How does one orchestrate & launch all of that on a laptop, especially the stateful services? Even if we could do it using stripped-down or API-compatible equivalents of the services, how could we be sure that the entire stack on a laptop behaves exactly like it does in the production environment?
Let’s say thanks to lots of elbow grease & ingenuity, we did manage to get it all working correctly, how would we keep the setup in sync with what’s running on production? It would get out-of-date very quickly since production looks so different from this stripped-down setup!
Not to mention, this entire approach of local development is a dead end as soon we start using cloud-native services like Lambda and DynamoDB that are only available in the cloud.
The Vision
So we asked ourselves if we should turn the conventional advice on its head and work towards a solution that doesn’t require developers to run our full wealth platform on their local machine. Developers shouldn’t bother testing anything more than at a unit or contract test level on their local machine. All remaining tests should be executed in an environment that is as close to production as possible.
With this renewed direction, we got to work on our vision to:
Build an environment for every team, for every project and every use case.
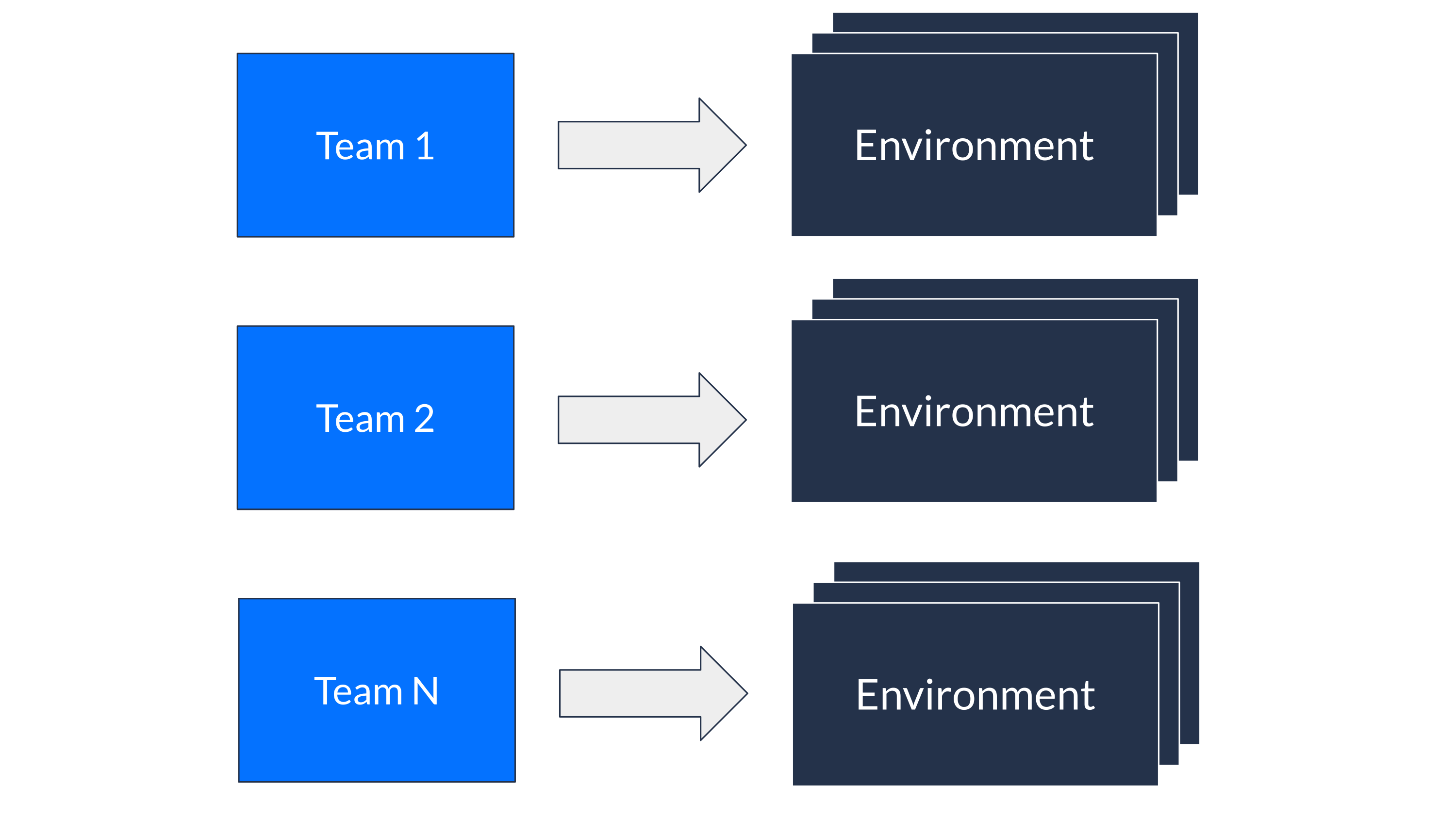
We didn’t come up with a fancy name and simply called these “dynamic environments”; a contrast to the static dev and staging environments.
Today
Dynamic environments have become the primary development & testing environment for all our engineers. The shared dev and staging environments haven’t been a bottleneck for a while, their usage is now limited as pre-prod testing environments.
Our engineers interact with their environments either through a self-service API or an internal developer portal. The self-service capabilities include operations like building and deploying a particular branch to the environment, populating it with synthetic data or resetting the environment to recover from a corrupted state.
The developer portal shows which services are running in an environment including git metadata that allows developers to easily identify what version of a service is running and how far behind the commit is behind the latest changes in the main branch. It also provides quick access to application logs, metrics and build information.
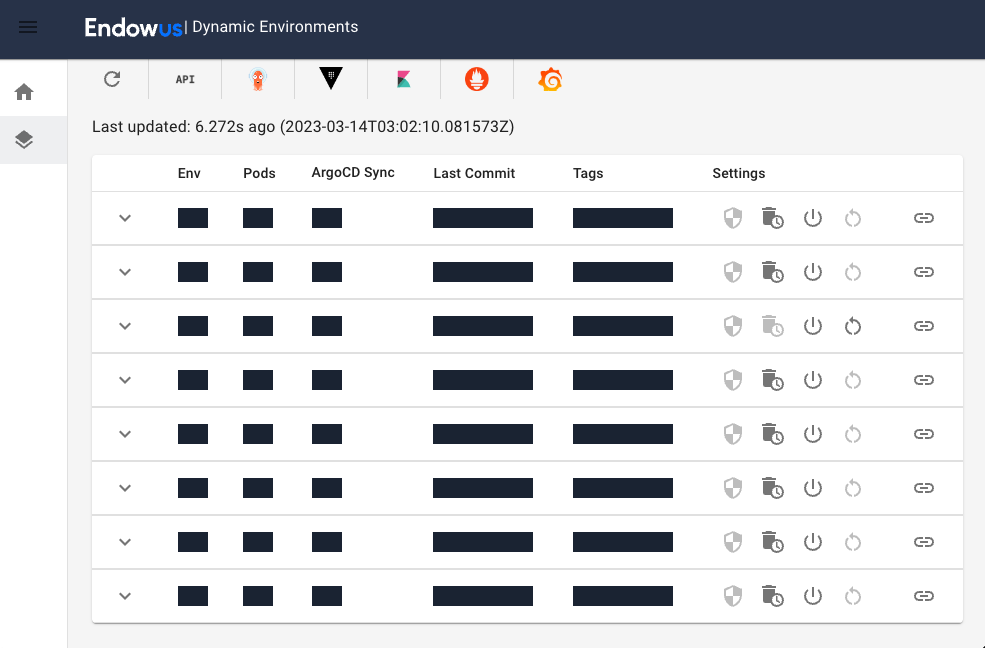
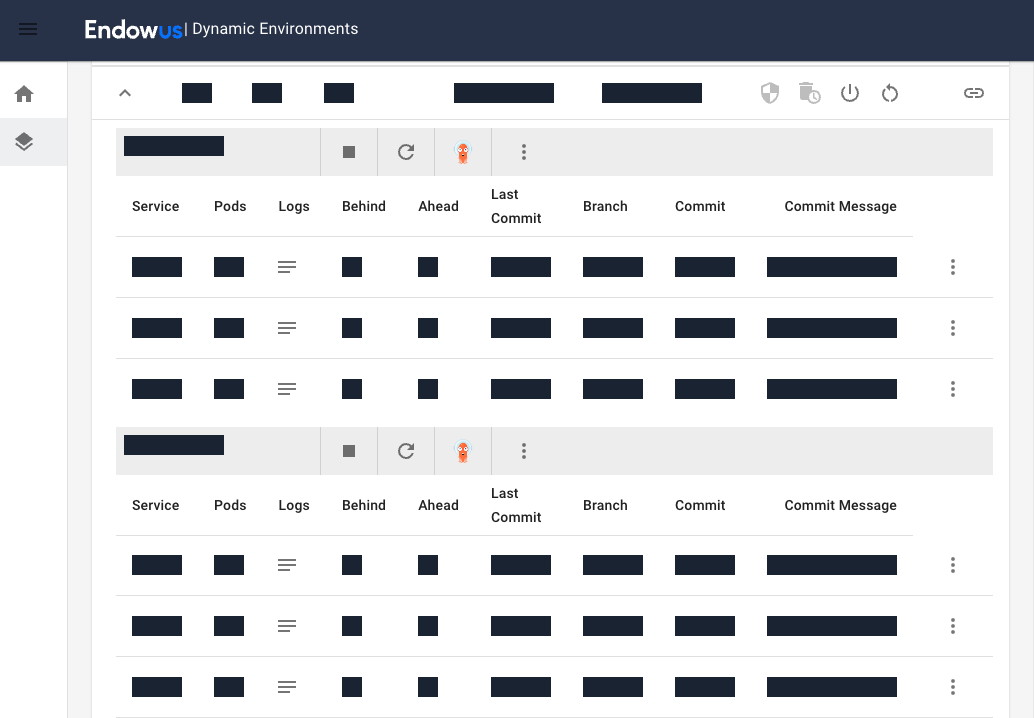
Today, we are able to provision a brand-new environment with our entire wealth platform deployed & running in under 30 minutes. Although technically we can spin up as many environments as needed (unlimited!), we often reuse an environment by cleaning up all the data and restoring the environment to a pristine state. This activity is even faster and we can reset an environment in under 10 minutes.
How did we build it?
When we started, we got a lot of pushback on this vision in the form of a few difficult questions as to why this idea of one environment for every team or every use case wouldn’t work:
-
It’s too hard to automate everything!
-
It’s too difficult to get developers to adopt a new way of working!
-
It’ll be too expensive to have so many environments running in the cloud!
Such questions are great at highlighting the key requirements and challenges to solve and that’s what we did!
Let’s dive into how we solved each of those challenges.
It’s too hard to automate everything!
The first objection was that it is too hard! It’s true. It is hard! That’s because it’s not just about automating the provisioning of the infrastructure services. We also need to automate the build & deployment of the applications and critically, the business data that makes an environment usable.

At the infrastructure layer, we leveraged managed services like Confluent Cloud, Datastax Astra, MongoDB Atlas and AWS Aurora to easily provision our Kafka and database resources. We use Terraform and designing our Terraform modules in an environment-agnostic way allowed us to reuse most of them for staging and production environment, thus keeping the parity between dynamic and non-dynamic environments as high as possible.
At the application layer, we needed to enable developers to be able to build and deploy a service from any branch to their target environment. A typical use case is to deploy a service from a feature branch while all other services are deployed from the main branch.
At the data layer, we needed to generate synthetic customer data for lots of different scenarios like newly signed up customers, partially onboarded and fully onboarded customers, etc.
To manage the application build & deployment as well as synthetic data generation, we developed an in-house control plane in Kotlin/Spring Boot which allowed us to control the lifecycle of an environment via self-service REST API or Web UI.
It’s too difficult to get developers to adopt a new way of working!
Having automated everything, the next challenge was to ask our developers to use the new environments for their day-to-day tasks and give up the existing dev and staging environments that they were used to.
In the abstract, getting our internal developers to adopt this new internal platform is no different than getting someone to adopt Endowus as their wealth advisor. Just like we take a thoughtful, product-centric approach to our customer-facing platform, we did the same for this internal dynamic environments platform. We started by treating internal developers as customers, understanding their requirements, developing new features and then seeking feedback.
We wrote loads of good documentation and did weekly demos for the teams to understand what’s new. To minimize the friction of adoption, we ensured that we use the same tech stack that our developers are used to for their production deployments, including tools like Hashicorp Vault, Kubernetes, Cassandra and the same CI/CD pipeline.
Moreover, we took the approach of Solutions Engineering in which we would periodically switch between the roles of product engineers and solution engineers. Some examples of solutions engineering are when we sat with the developers and co-engineered solutions like making an application less dependent on a specific environment or generating synthetic data for a specific use case.
Taking this product mindset was key to driving the adoption of this new platform.

It’ll be too expensive
Finally, let’s talk about cost. On the surface, it may seem crazy to spin up so many production-like environments in the cloud. Companies already struggle with managing their cloud spendings and having to manage even more environments certainly seems like madness!
However, cloud cost management is already a discipline that companies (need to) practice and all of the techniques typically used to manage cloud costs can also be applied to managing costs of our dynamic environments!
These are just some of the more impactful cost management techniques we’ve used:
-
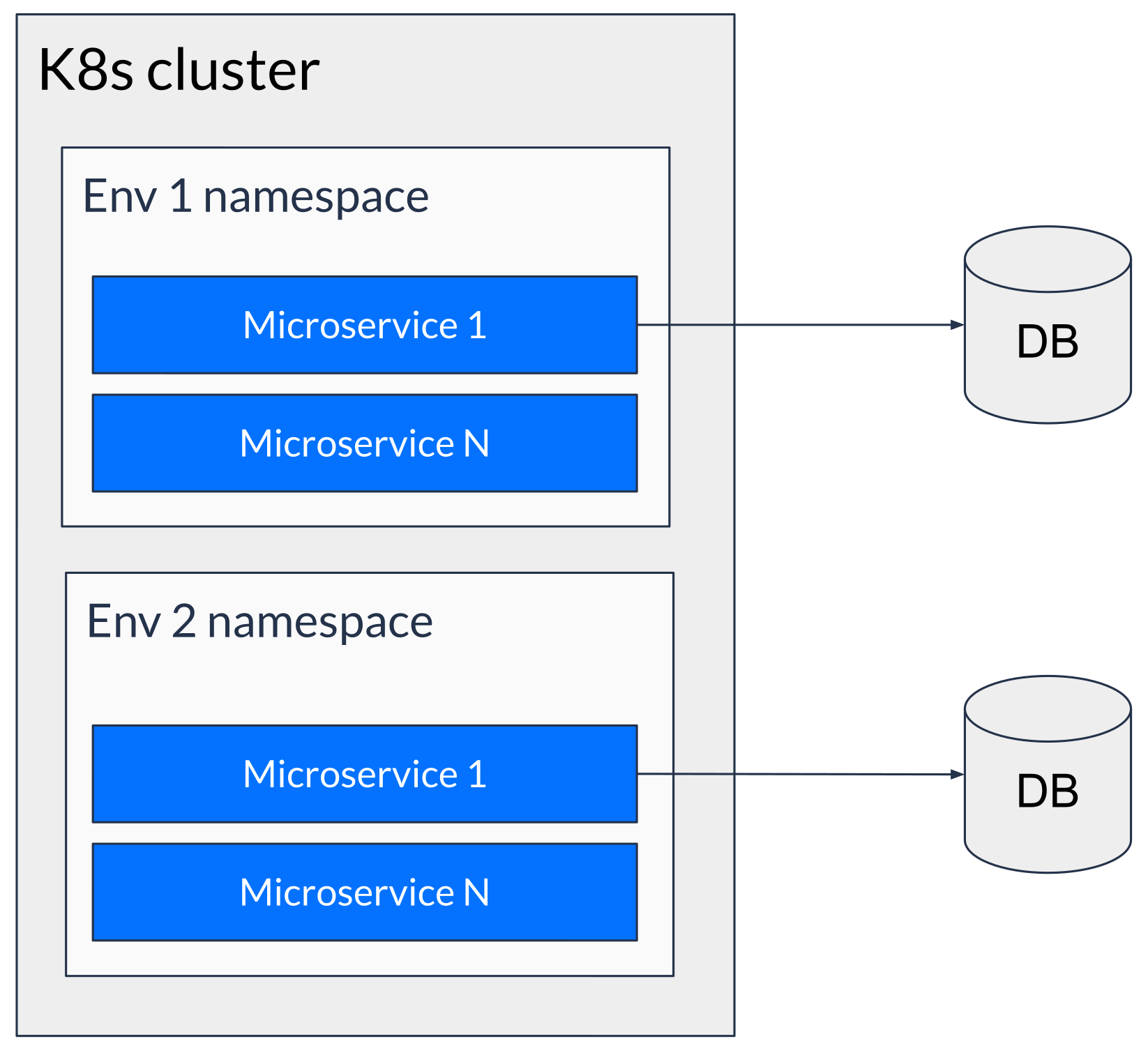
We use Kubernetes namespaces as the environment isolation construct. All our dynamic environments are hosted in a single Kubernetes cluster, isolated by namespaces, thus amortizing the control plane cost while driving up the density and utilization of the nodes.
-
We also use Karpenter to autoscale the Kubernetes cluster. Since all our environments are in the same cluster, Karpenter can manage & scale resources across all of our dynamic environments instead of just within an environment.
-
Unlike production, we deploy services in a single AZ config significantly reducing our spending on managed services. We also use lower specced and cheaper compute and database instances for dynamic environments, further driving down costs.
-
Where available, we use the serverless variants of services that scale to zero and thus reduce costs in low usage environments.
Today, our dynamic environments all together cost us about 30% of what we spend on production. This is a great value considering the engineering productivity we have achieved due to this spending.
What’s next
The next big developer experience investment we are making is to deeply integrate dynamic environments into our performance and regression testing frameworks, further enhancing our continuous deployment and delivery capabilities.
More on that in a future blog post!