Have you ever faced the dreaded “OOMKilled” (Out Of Memory Killed) message in your Kubernetes environments? If so, you’re not alone!
In this post, we’ll dive into a real-world scenario where some of our backend services faced exactly this challenge. We’ll unpack what happened, how it was investigated, and the lessons learned. We have tried to keep it understandable even if you’re not a JVM or Kubernetes expert. Feedback welcome!
A Quick TL;DR
In essence, our backend services were getting OOMKilled due to exceeding the assigned container memory usage limits. The crux of the issue? A blanket allocation of 80% of container memory to the JVM heap, without adequately considering off-heap memory usage. The solution? More nuanced memory limit settings per backend service based on usage profile and a reduction in JVM heap memory allocation to make room for off-heap usage.
Our Backend Setup: A Primer
Before diving into the issue, let’s set the stage with an overview of our backend infrastructure.
Our backend comprises nearly three dozen microservices that work together using event sourcing to manage all of the complexity & functionality of our digital platform.
- Language and Framework: Our services are written in Scala, leveraging the Akka framework. This choice provides us with robust concurrency and distributed system capabilities.
- Containerized with Kubernetes: All services run in containers, orchestrated by Kubernetes. This setup offers scalability and efficient resource management.
- Multiple Environments and Regions: We operate in various environments like staging and production, spread across regions like Singapore and Hong Kong to serve the different markets where we operate our business.
- Monitoring Tools: We use Prometheus and Grafana for monitoring, collecting a plethora of metrics, including Java Virtual Machine (JVM) metrics, which are critical for understanding memory usage patterns.
Observations from our Data
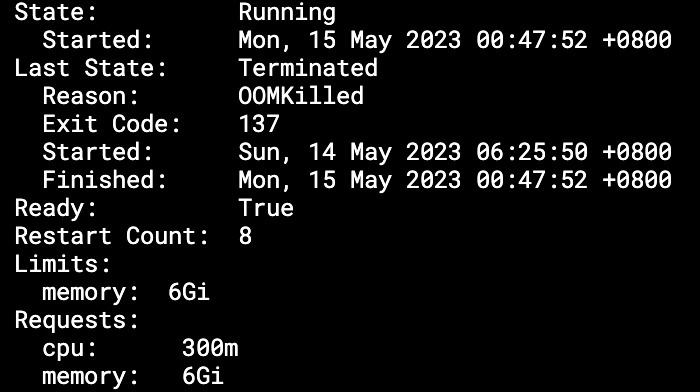
As we mentioned at the beginning, many of our backend services were getting terminated regularly by Kubernetes due to exceeding memory limits.
The Grafana screenshot above shows memory usage metrics for one of our
services named rebalance. This service is responsible for rebalancing
client portfolios whenever they deviate from their target asset allocation.
This service with a 6GB container was regularly hitting the memory ceiling. You can see it in the screenshot where the committed heap usage kept growing before the service was OOMKilled, as indicated by the drop to zero.
The JVM max heap was configured to 80% of container memory
(-XX:MaxRAMPercentage=80)
and we could see that the actual heap usage (peaking at 4.37GB
before the container was killed), was well within that 80% (4.8GB)
limit.
This indicated that approximately 1.63GB (6GB - 4.37GB) was being used off-heap. But how and why?
JVM and Off-Heap Memory Analysis
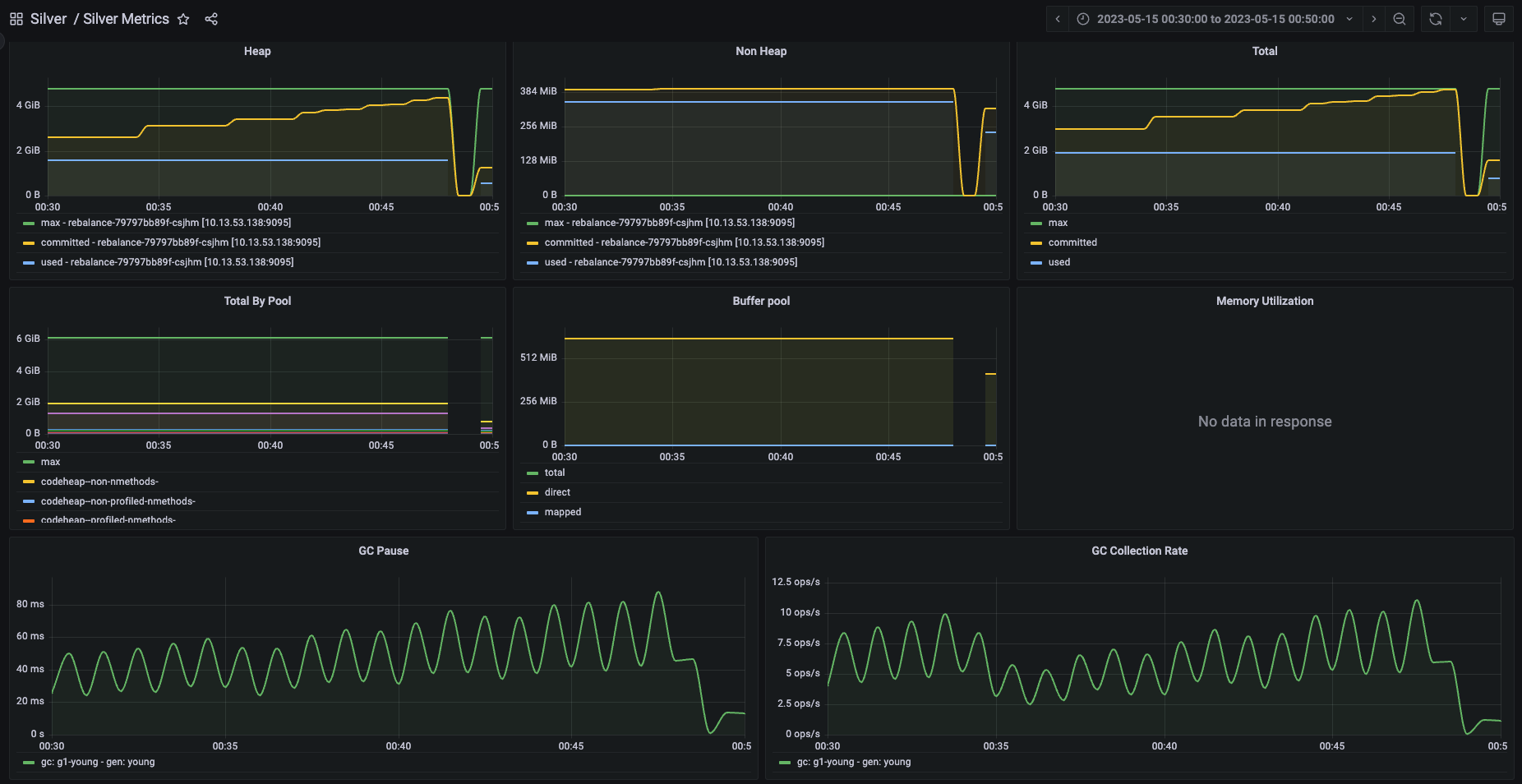
Our Grafana dashboards which are populated with JVM reported metrics already show “Non Heap” and “Buffer pool” usage in separate visualizations. If you look at the screenshot above once again, you’ll see that about 346MB was used out of about 397MB committed for off-heap usage. Together with another ~630MB used in buffer pool, total reported off-heap memory usage only adds up to 1027MB which is clearly quite a bit lower than the 1.63GB actual usage from container memory metrics!
To get a more detailed breakdown of this usage, we turned to a JVM feature named Native Memory Tracking.
Native Memory Tracking is disabled by default and can be enabled by
passing the flag -XX:NativeMemoryTracking=summary. Once enabled, we
can get a current snapshot of native memory usage:
$ kubectl exec rebalance-844cf67689-fz6bg -- jcmd 1 VM.native_memory
[... detailed NMT output ...]We’ve elided the detailed NMT output for brevity but what this detailed
breakdown revealed was that Non-Heap pools reported in JVM metrics only
contain the basic data, such as codeheap-non-nmethods,
codeheap-non-profiled-nmethods, codeheap-profiled-nmethods,
compressed-class-space, metaspace, etc. However, they do not include
memory used by the garbage collector itself. This additional GC
allocation comes up to about 100-150 MB as the committed heap grows, and
helps to partially explain the extra off-heap usage.
The other significant usage of memory – around 630MB – was in direct byte buffers. These are typically allocated for more efficient memory management than afforded by the garbage collector. Usage of these buffers to such an extent was surprising since our code didn’t explicitly use them, pointing towards library usage.
Now tuning the off-heap memory used by the G1 GC is not something that we have control over. So at this point, we knew that diving into the rather considerable byte buffer usage would give us the best bang for buck in getting a handle on this OOM issue.
Do ByteBuffers directly cause OOMKilled?
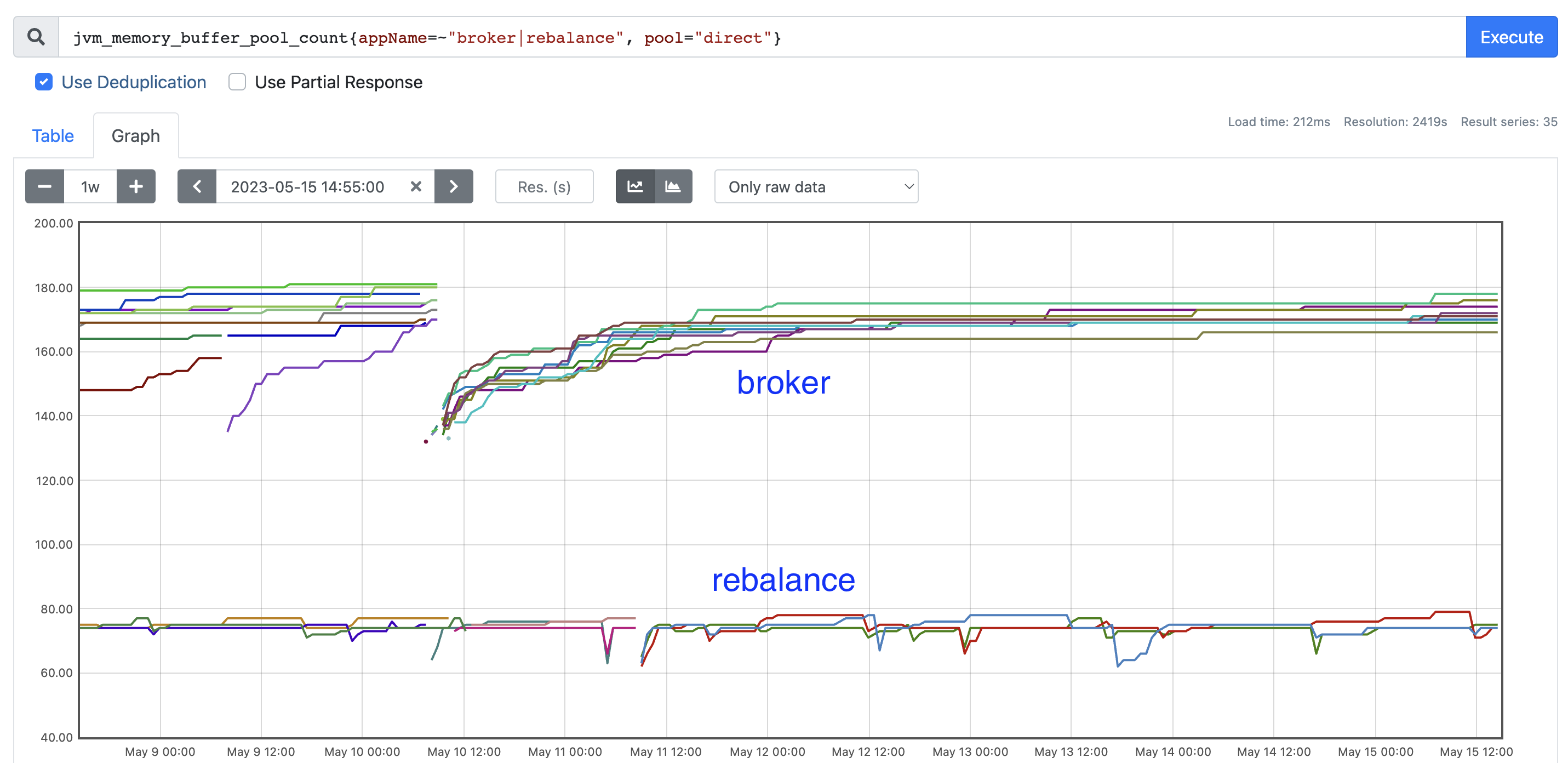
As mentioned earlier, our backend platform comprises nearly three dozen microservices. Repeating the above memory allocation analysis for all these services revealed that every single one of these had a significant memory allocation in byte buffers. Yet, not every service was equally affected by OOMKilled issues.
When we looked at the allocation profile, we saw that the number of Direct ByteBuffers quickly increases from startup and then stabilises after a while. Post startup and during runtime operations, the demand for more memory within the JVM does not originate from byte buffer allocations. Instead, it originates from regular heap allocations. But since not enough real heap memory is available (with byte buffers and other non-heap usage already having consumed more than expected), the JVM gets OOMKilled.
Thus, whether a service is more or less likely to get OOMKilled is determined by how heap memory is consumed during runtime:
- For services where the load comes in smaller chunks throughout the day
(e.g. our
onboardingservice which handles new client signups), the JVM is less likely to commit more heap. Hence, we can “fix” OOMKilled for this type of services just by allocating much more container memory than really needed. - For services where the load comes in huge bursts (e.g. our
rebalanceservice when market values change significantly triggering a portfolio rebalance), the JVM is more likely to commit more heap (even though used heap is not increasing). This G1 heuristic of committing more heap in anticipation due to a bursty workload leads to OOMKilled. There is simply not enough memory left in the container. - For services that are very lightly loaded (e.g.
instrumentwhich just needs to lookup and return reference data - a constant time/space operation), we allocate only 2GB container memory. Based on our defaults (-XX:MaxRAMPercentage=80), we expect 1.6GB allocated for heap and 0.4GB for non-heap usage. However, direct bytebuffers would already use >500MB right after startup. Thus, even a little more than the baseline load causes the JVM to commit more memory, triggering OOMKilled.
Delving Deeper: ByteBuffer Usage
In order to rein in OOMKilled issues, we really had to understand our byte buffer usage. To do so, we first had to dump the heap of the JVM process for offline analysis.
Taking a heap dump
In a Kubernetes environment, a JVM heap dump can be take quite easily:
$ kubectl exec rebalance-844cf67689-fz6bg -- jmap -dump:live,format=b,file=/tmp/dump.hprof 1
$ kubectl exec rebalance-844cf67689-fz6bg -- tar -czvf /tmp/dump.hprof.tar.gz /tmp/dump.hprof
$ kubectl exec rebalance-844cf67689-fz6bg -- cat /tmp/dump.hprof.tar.gz > heap_dump/rebalance-844cf67689-fz6bg.tar.gzUsing tar to compress the dump file is necessary as the raw heap dump is really large (~500MB) and it gets easily corrupted even with kubectl cp command.
Offline analysis of heap dump
There are many tools that can be used to analyse a heap dump file. We used VisualVM because it supports OQL which makes it easier to search, especially when we already know what we are after.
To query all java.nio.DirectByteBuffer objects:
select map(
sort(
filter(
heap.objects('java.nio.DirectByteBuffer'),
'count(referees(it)) == 0'
),
'rhs.capacity - lhs.capacity'
),
'{ bb: it, capacity: it.capacity }'
)The Heap dump analysis revealed three significant usages of byte buffers in our services.
JImage ImageReader

jdk.internal.jimage.ImageReader$SharedImageReaderThe first significant usage was in JImage ImageReader. This is used by JDK9 onwards to load modules. This is the first byte buffer that’s allocated (DirectByteBuffer#1) suggesting that it is used
during the JVM’s initialization phase. Interestingly, this memory usage
is captured neither in JVM metrics nor in NMT summary. This leads to
further errors in our estimation of heap vs non-heap memory usage and
allocation.
There’s not much we can do about this usage other than ensuring that we budget for it correctly.
Akka remote Artery EnvelopeBuffer
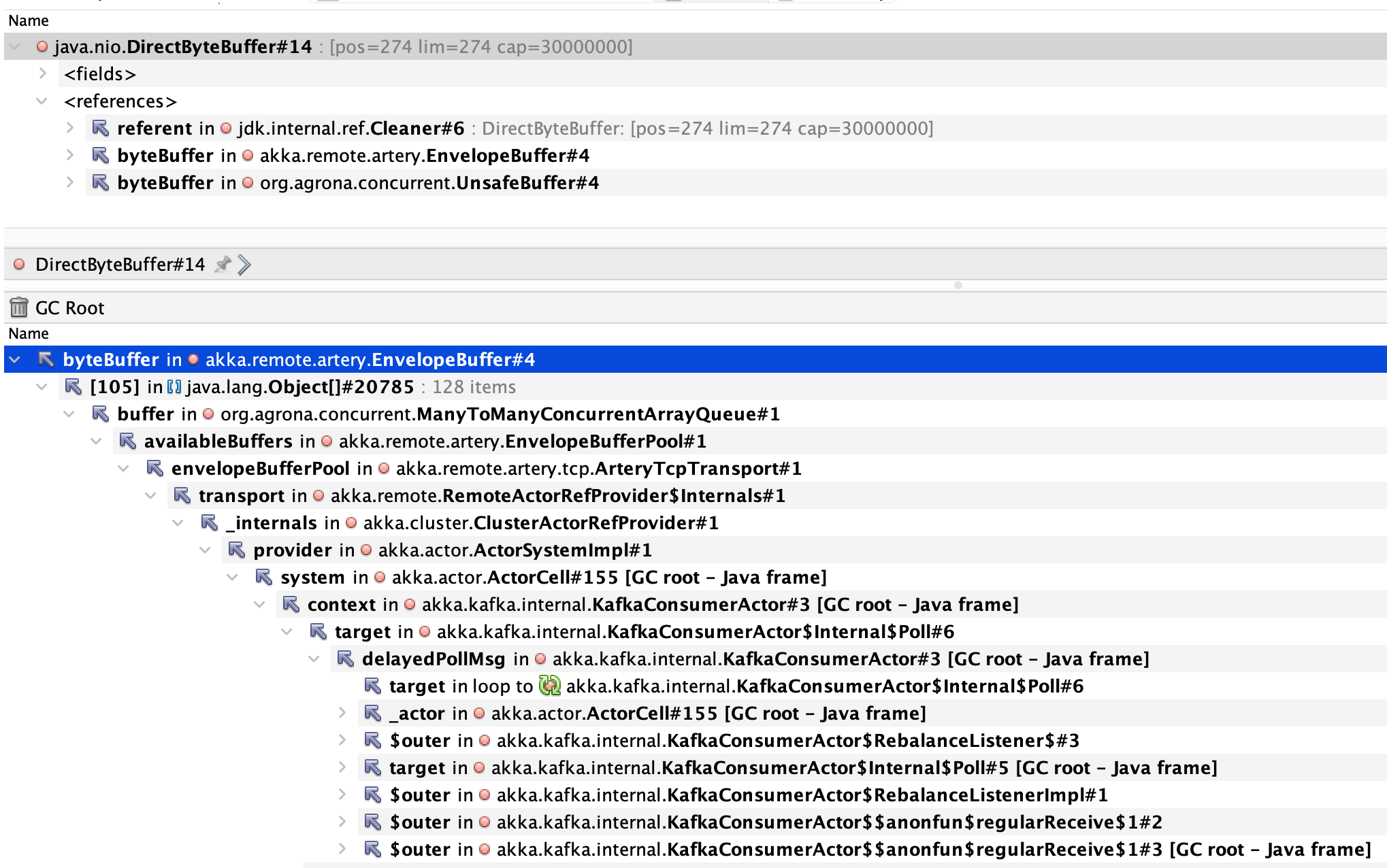
akka.remote.artery.EnvelopeBuffer allocationsAs we mentioned in the backend setup section, our services use the Akka
framework. Within Akka, the actor pattern is used to implement event
sourcing and these actors use akka.remote.artery.EnvelopeBuffer to
communicate with each other in the cluster. Each of these buffers is of
size 30,000,000 bytes or nearly 28 MiB.
There are a couple of Akka configuration settings that affect this buffer usage:
akka.remote.artery.advanced.buffer-pool-size= 128 (default)- This controls the maximum number of buffers to allocate and keep around.
- Usually, these buffers are reused but if the service needs more buffers than currently available, Akka will still create more, but anything exceeding 128 will be cleaned right after usage.
- We were not overriding the default value of 128.
akka.remote.artery.advanced.maximum-frame-size= 256 KiB (default)- This controls the size of each buffer that’s created.
- Due to some historical legacy issues with large entity events, we were overriding the 256KiB default to 28MiB.
Based on our configuration, max off heap usage could grow as large as
128 * 30,000,000 bytes ~= 3.6GB which would guarantee an OOMKilled event
even before we hit the 128 buffer pool size.
Cassandra Datastax driver’s Netty buffers
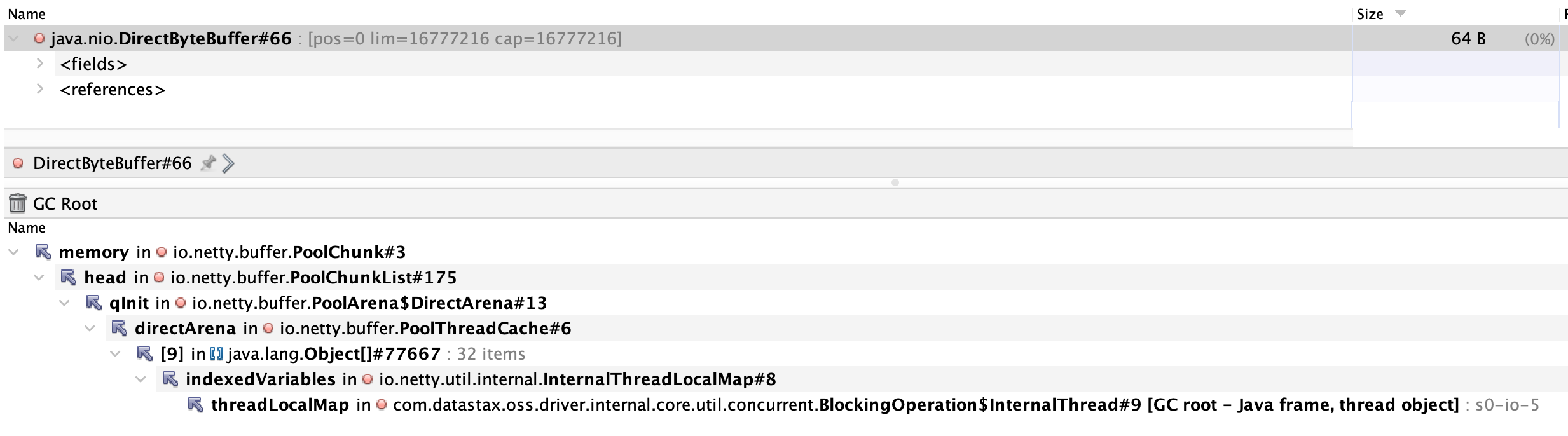
io.netty:netty-buffer PooledByteBufAllocator allocationsOur primary database is Cassandra and it’s used by Akka via the
akka-persistence-cassandra library. Communication with Cassandra is
managed by the Datastax Cassandra driver. This driver makes use of
io.netty:netty-common FastThreadLocalThread, which in turns uses
io.netty:netty-buffer PooledByteBufAllocator. By default, this allocator
would create:
availableProcessors() * 2 = 8 * 2 = 16chunks- This can be overridden by setting the System property
io.netty.allocator.numDirectArenas
- This can be overridden by setting the System property
- each have size
pageSize << maxOrder=8192 << 11= 16,777,216 bytes or 16 MBpageSizeis configurable via System propertyio.netty.allocator.pageSizemaxOrderis configurable via System propertyio.netty.allocator.maxOrder
Neither us nor the Datastax library was overriding any of these. Thus, this usage would consume 256 MB off-heap upon driver initialization for every service and this too needed to be factored into JVM off-heap memory sizing.
Killing the OOMKilled
Armed with the insights that this analysis revealed, we identified two sets of changes.
The first set of changes were across the board wherein we revisited our approach of allocating 80% of container memory to the heap and made it more nuanced to the nature of each microservice:
- for small services with little load: use 2GB container with 50% for heap
- for services with higher load: use 4GB container with 60% for heap
- for services with higher load + large messages: use 8GB container with 70% for heap
Essentially, we kept the overall container memory for each service at the same level but allocated more of it for non-heap usage.
The second set of changes were focussed on tweaking Akka messaging configuration based on each microservice’s specific messaging patterns:
- Instead of a common buffer size for all our backend services, set the
maximum-frame-sizefor each service with a value that’s appropriate for the messages handled by that specific service. - For the services that do handle large messages, set
akka.remote.artery.large-message-destinationsso that the larger buffers are only used for specific messages, even within a single service. - Finally, set the upper bound of
buffer-pool-sizeto a value much lower than the default of 128. The exact value varies per service and is determined using actual usage metrics gleaned fromjvm_memory_buffer_pool_count
The alert reader may have noticed that the screenshots shared in this post are from May 2023 while this post was published in December 2023. We’ve been progressively rolling out these changes in production over the last several months and tweaking things along the way based on continued observations. We are happy to share that the frequency of these errors has reduced to such an extent that we feel we’ve really killed the OOMKilled, at least for now!
Conclusion: Embracing the Complexity of Memory Management
Monitoring and Analysis: A Necessity
The complex nature of memory usage in JVM-based applications, especially those using frameworks like Akka, necessitates comprehensive monitoring and detailed analysis. Tools like Prometheus and Grafana, coupled with native memory tracking and heap dump analysis, are indispensable.
Memory Allocation Strategy: Rethinking
Our initial approach of allocating 80% of container memory to the JVM heap didn’t consider off-heap usage. The data clearly indicated the need for a more nuanced strategy, tailored to each service’s specific memory usage profile.
One of the key revelations was the extensive use of Direct ByteBuffers by our libraries. These buffers reside outside the JVM heap and were not accounted for in our initial memory allocation strategy.
Key Takeaways and Recommendations
Based on our findings, we recommend:
- Lowering JVM Heap Allocation: Start with a more conservative allocation for JVM heap memory to accommodate off-heap usage.
- Service-Specific Memory Limits: Each service should have memory limits based on its unique profile, derived from thorough monitoring and analysis.
- Regular Heap Dump Analysis: Regular analysis of heap dumps can uncover unexpected memory usage patterns and help in optimizing memory allocation.
- Continuous Monitoring and Iteration: Memory management is not a ‘set and forget’ task. Continuous monitoring and iterative adjustments are key to optimal performance.
Through this deep dive into memory management challenges in our backend services, we’ve seen how intricate and crucial proper memory allocation and monitoring are. By understanding the nuances of JVM and container memory usage, and by leveraging the right tools and strategies, we can ensure that our services run reliably, even under heavy load.
Keep exploring, keep optimizing, and may your services never be OOMKilled again!